淘天视觉AIGC面试题库
- 2026-04-01 02:37:42
淘天视觉AIGC面试题库
(1)self attention和cross attention的区别? 参考答案: Self-Attention(自注意力)和Cross-Attention(交叉注意力) 是Transformer架构中两种核心的注意力机制,它们的主要区别在于处理的数据源不同。 随机性采样 - 基于随机微分方程
代表性方法:DDPM。 代表性方法:DDIM、PLMS。 代表性方法:DPM-Solver、UniPC、LCM / LCM-LoRA。 (3)讲讲Imagen。 参考答案: 这是由Google Research在2022年发布的文本到图像生成模型,以其惊人的图像质量和精准的文本对齐能力而闻名。 Imagen最引人注目的特点是:没有使用CLIP等预训练的文本编码器,而是直接使用大型语言模型(LLM)作为文本理解的核心。 (4)LoRA原理? 参考答案: LoRA 的原理,这是一种高效的大模型微调技术,在Stable Diffusion时代变得极其流行。 LoRA的核心创新可以用一句话概括:不直接微调整个大模型的权重,而是通过注入可训练的、秩很低的分解矩阵来实现微调。 (5)Rectified flow是什么?如何实现一步生成? 参考答案: 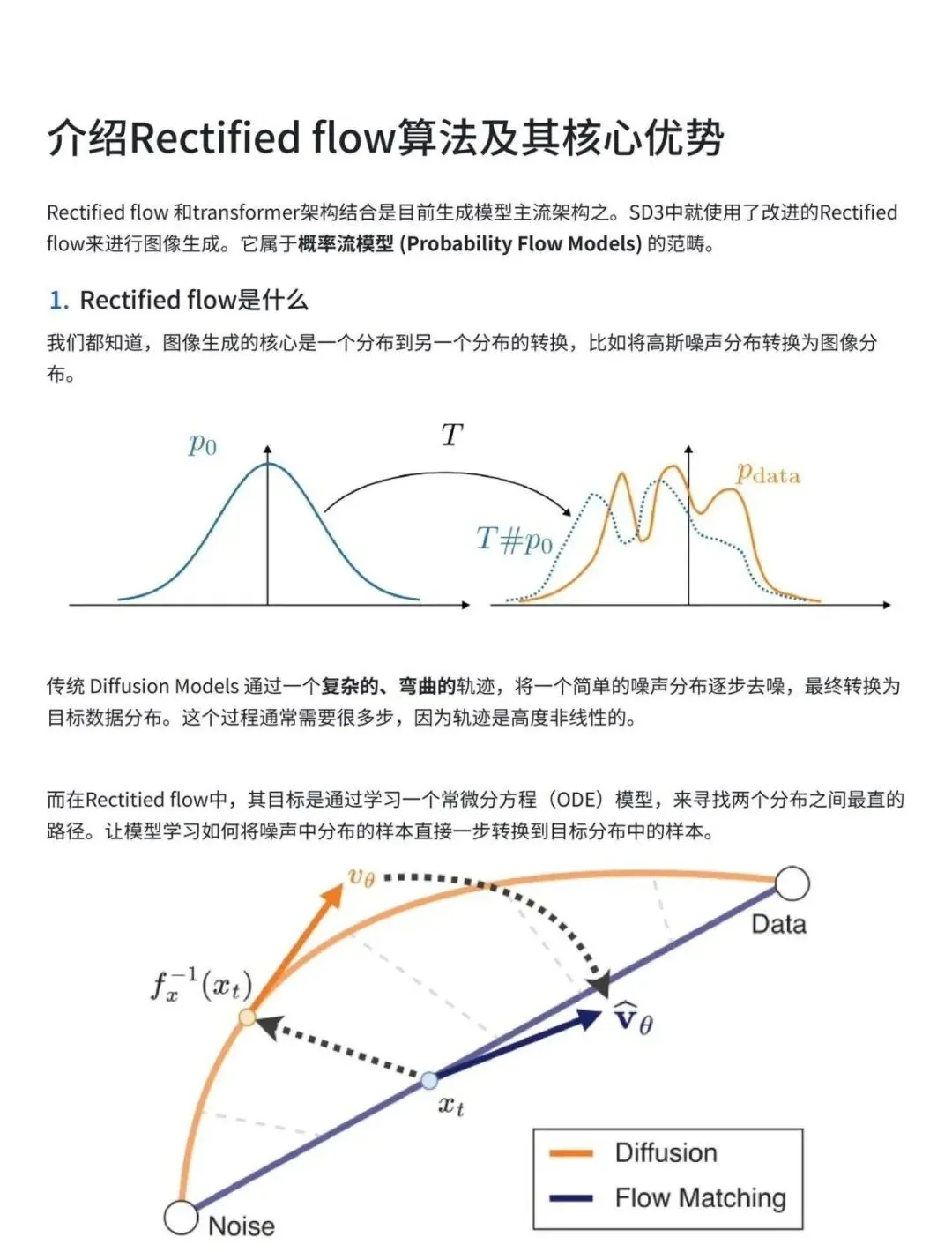


相关文章推荐: 字节跳动AIGC面试题库
Self-Attention(自注意力):核心思想是让序列中的每个元素(例如一个单词)去查看整个序列,找出与它最相关或最需要注意的其他元素,从而更新自己的表示。(自省)
Cross-Attention(交叉注意力):核心思想是让一个序列(查询序列)中的元素,去“查询”或“关注”另一个序列(**源序列”)中与之相关的信息,并将这些信息融合过来。(外交)
(2)Diffusion采样方式有哪些?
参考答案:
Diffusion模型的采样方法 主要可以分为两大类:确定性采样和随机性采样。
随机性采样 - 基于随机微分方程这类方法遵循扩散过程的随机性本质,在采样过程中引入噪声。
确定性采样 - 基于常微分方程
这类方法将随机扩散过程重新参数化为一个确定性过程(ODE),从而消除采样中的随机性。
快速采样专用方法
这类方法专门为极大幅减少采样步数而设计,通常结合了数学上的高阶求解技术。
Imagen的核心创新在于将最先进的自然语言理解模型(T5)直接整合到图像生成流程中,这反映了谷歌的一个关键理念:文本到图像生成的核心是语言理解问题。尽管它没有像Stable Diffusion那样开源并引发社区爆炸,但它在技术深度和质量标杆方面的影响是深远的。
Imagen证明了:
扩大文本编码器比扩大图像解码器更有效
纯扩散模型可以生成接近照片级真实的图像
级联结构和条件增强是关键的质量保障
对于想要深入理解现代文本到图像技术的人来说,Imagen的设计理念和实验结果提供了宝贵的见解,特别是关于文本表示如何影响生成质量这一根本问题。
为什么需要LoRA?
在LoRA出现之前,微调大模型面临两大挑战:
内存消耗巨大:需要存储完整的模型梯度、优化器状态等
存储成本高:每个微调任务都需要保存一份完整的模型副本(通常几十GB)
LoRA解决了这两个问题!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【考证刷题】25年全国通用党章考试题库及答案(4)
- 【考证刷题】25年全国通用党章考试题库及答案(4)
- 【考证刷题】25年全国通用入党考试题库小程序(9)
- 产品策划面试题库高频60题
- 知云题库:叉车司机考证必刷!这50道精准题目帮你一次通关
- 【27考研】灰灰计算机小程序刷题库!
- 安徽中医药大学考研初试资料大合集:配套题库【名校考研真题+课后+章节+模拟试题】
- 安徽中医药大学考研初试资料大合集:配套题库【名校考研真题+课后+章节+模拟试题】
- 26届自动化考研复试《强化班C语言题库》(杨戬篇)甄选部分①
- 26届自动化考研复试《强化班C语言题库》(杨戬篇)甄选部分①
